# 开放地址法

了解下就OK,这货比链地址法(拉链法)可麻烦的一批
开放地址法其实就是寻找空白的位置来放置冲突的数据。探索这个位置的方式有三种:
线性探测
二次探测
再哈希化
# 线性探测
线性的查找空白单元
插入32,经过哈希化得到 index = 2,但是在存放这个数据的时候,发现 2 这个位置已经有了82,怎么处理呢? 线性探测就是从index位置+1,开始一点点查找到合适的位置来存放32,那么什么是合适的位置呢? 空的位置就是合适的位置。此处 index = 3 这个位置就是存放32 的位置。
查询32,查询32和插入32的过程比较相似,首先经过哈希化得到index = 2, 取出2位置的数据和查询的数据比较是否相同,相同则直接返回。 如果不相同,线性查找,从 index 位置+1 开始查找和32一样的数据。注意,如果index=3的位置应该存放32这个数据,但是没有存放, 这个时候是否要将整个哈希表查询一遍来确定32是否存在不存在呢?当然不用,查询过程有一个约定, 就是查询到
空位置,就停止。
删除 32,删除操作和插入以及查询比较类似,但是有一个特别注意的点。 删除操作一个数据时候,不可以将这个位置的内容设置为 null, 因为可能会影响查询其他数据的操作(比如62),所以通常删除一个位置的数据时, 可以将其进行特殊处理,比如设置为 - 1。
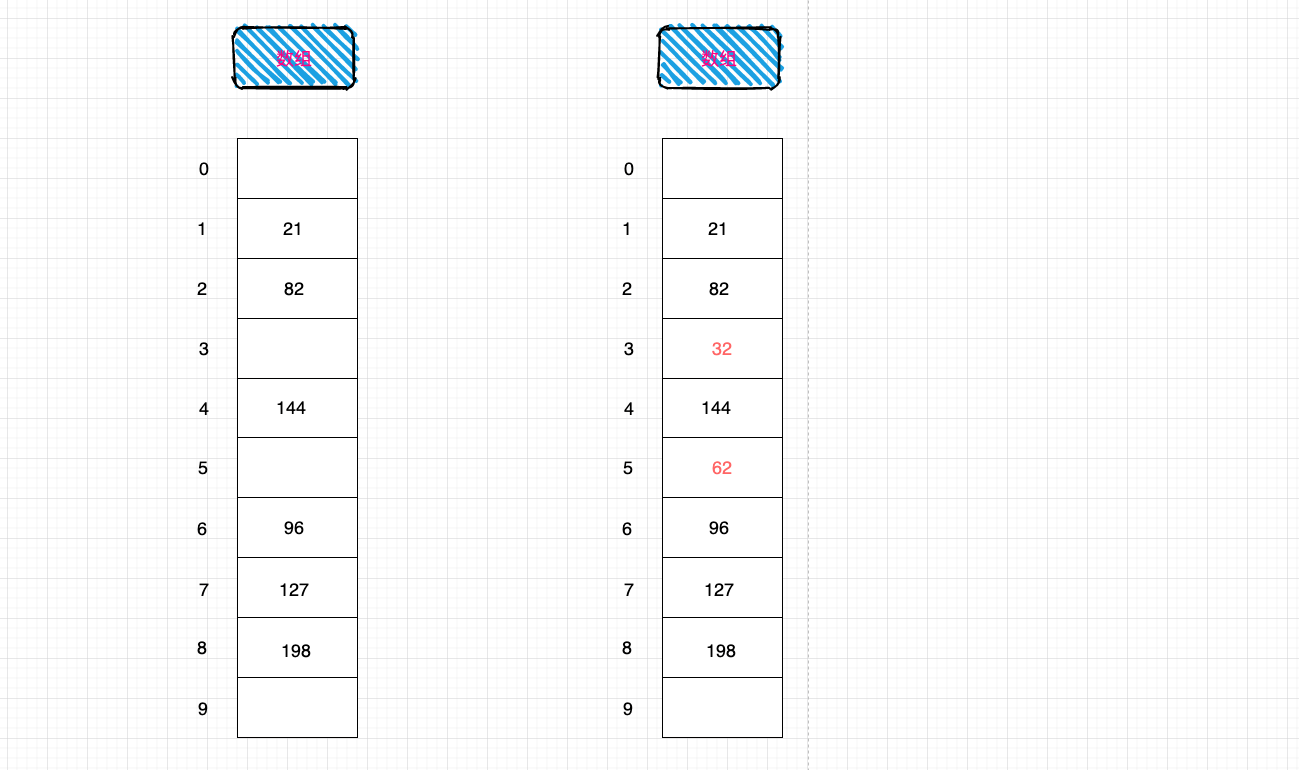
插入 32 和 62来个数据
线性探测的问题:
线性探测有一个比较严重的问题,就是聚集,什么是聚集呢? 比如在没有任何数据的时候,插入的是22-23-24-25-26,那么意味着下标值为2-3-4-5-6的位置都有元素了,这种一连串填充单元就叫做聚集。
聚集会影响哈希表的性能,无论是查插入、查询、删除都会有影响。 比如需要插入32时候,会发现连续的单元都不允许放置数据。并且在这个过程中需要探索多次。
二次探测可以解决一部分这个问题。
# 二次探测
线性探测存在的问题,如果之前的数据是连续插入的,那么新插入的数据可能需要探测很长的距离。
二次探测在线性探测的基础上进行了优化,主要优化的是探测时的步长。
线性探测可以看成是步长为1的探测,比如从下标值x开始,那么线性探测就是 x + 1, x + 2, x + 3 依次探测。
二次探测,对步长做了优化,比如从下标值x开始,x + 1^2 、x + 2^2 、 x + 3^2。这样就可以一次性他侧比较长的距离。避免那些聚集带来的影响。
二次探测的问题:
连续插入32-112-82-2-192,那么他们依次累加的步长是相同的。也就是这种情况下会造成步长不一的一种聚集。还是会影响效率(这种可能性相对于连续的数字会小一些)。
怎么根本解决这个问题呢?让每个人的步长不一样,一起来看看再哈希化吧。
# 再哈希化
为了消除线性探测和二次探测中无论步长+1还是步长+平方中存在的问题,还有一种常用的解决方案,再哈希化。
二次探测的算法产生的探测序列步长是固定的,1、4、9、16依次类推。
那么,不同的关键字即使映射到相同的数组下标,也可以使用不同的探测序列。
再哈希化的做法就是,把关键字用另外一个哈希函数,在做一次哈希化,用这次哈希化的结果作为步长
对于指定的关键字,步长在整个探测中是不变的,不过不同的关键字使用不同的步长。
第二次哈希化需要具备以下特点:
和第一个哈希函数不同
不能输出为0 ,否则将没有步长,每次探测都是在原地踏步,就会进入死循环。
其实我们不需要费脑细胞来设计,计算机专家已经设计出一种工作很好的哈希函数。
stepSize = constant - (key % constant)
// 其中 constant 是质数,且小于数组的容量
// 例如:stepSize = 5 - (ley % 5) 满足需求,并且结果不为0
2
3
4
5
# 哈希化的效率
哈希表中执行插入和搜索操作的效率是非常高的
- 如果没有产生冲突,那么效率就会更高。
- 如果产生冲突,存取时间就依赖后来的探测长度。
- 平均探测长度以及平均存取时间,取决于装填因子,随着装填因子变大,探测长度也越来越长。
装填因子:表示当前哈希表中已包含的数据项和整个哈希表长度的比值。
装填因子 = 总数据项 / 哈希表长度。
开发方地址发的装填因子最大是1,因为他必须寻找到空白的单元才能将元素放入。
链地址法的装填因子可以大于1,因为链地址法可以无限的延伸下去,当然越往后效率就会变低。
# 不同探测方式性能比较
线性探测
下面的等式显示了线性探测时,探测序列(P)和填装因子(L)的关系
对成功的查找: P = (1+1/(1-L))/2
对不成功的查找: P=(1+1/(1-L)^2)/2
公式来自于Knuth(算法分析领域的专家, 现代计算机的先驱人物)
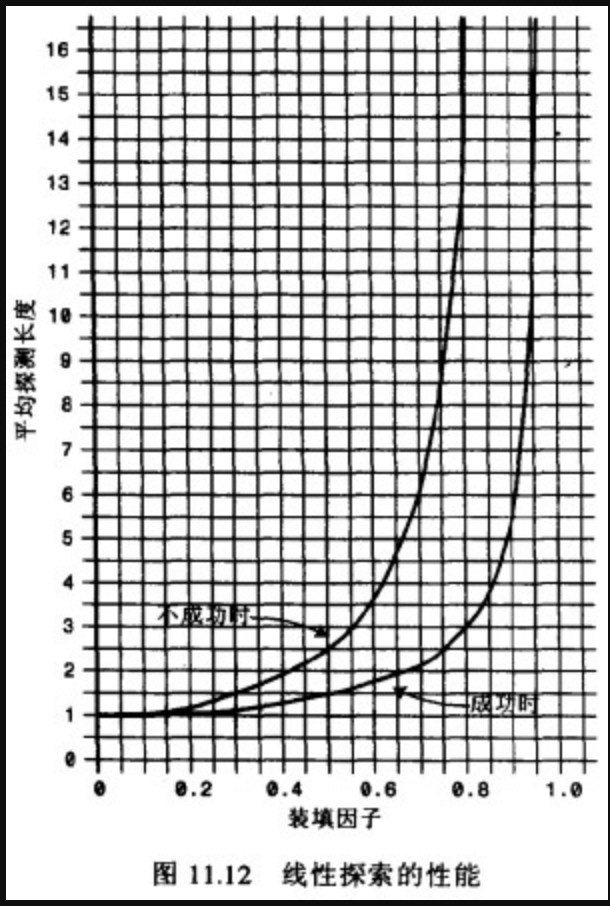
- 当填装因子是1/2时,成功的搜索需要1.5次比较,不成功的搜索需要2.5次
- 当填装因子为2/3时,分别需要2.0次和5.0次比较
- 如果填装因子更大,比较次数会非常大。
- 应该使填装因子保持在2/3以下,最好在1/2以下,另一方面,填装因子越低,对于给定数量的数据项,就需要越多的空间。
- 实际情况中,最好的填装因子取决于存储效率和速度之间的平衡,随着填装因子变小,存储效率下降,而速度上升。
二次探测和再哈希
二次探测和再哈希法的性能相当。它们的性能比线性探测略好。
对成功的搜索,公式是: -log2(1 - loadFactor) / loadFactor
对于不成功的搜搜, 公式是: 1 / (1-loadFactor)
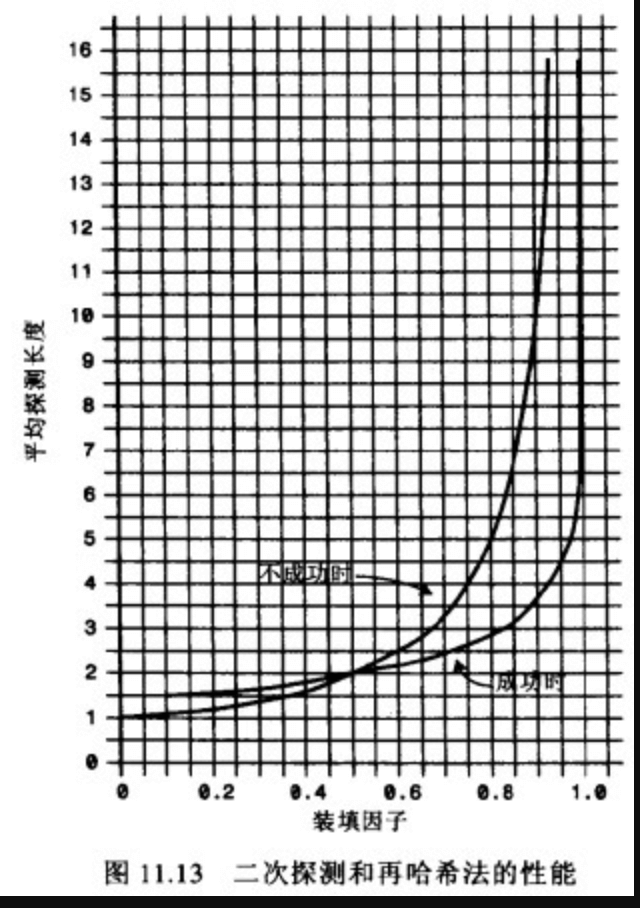
- 当填装因子是0.5时,成功和不成的查找平均需要2次比较
- 当填装因子为2/3时,分别需要2.37和3.0次比较
- 当填装因子为0.8时,分别需要2.9和5.0次
- 因此对于较高的填装因子,对比线性探测,二次探测和再哈希法还是可以忍受的。
链地址法
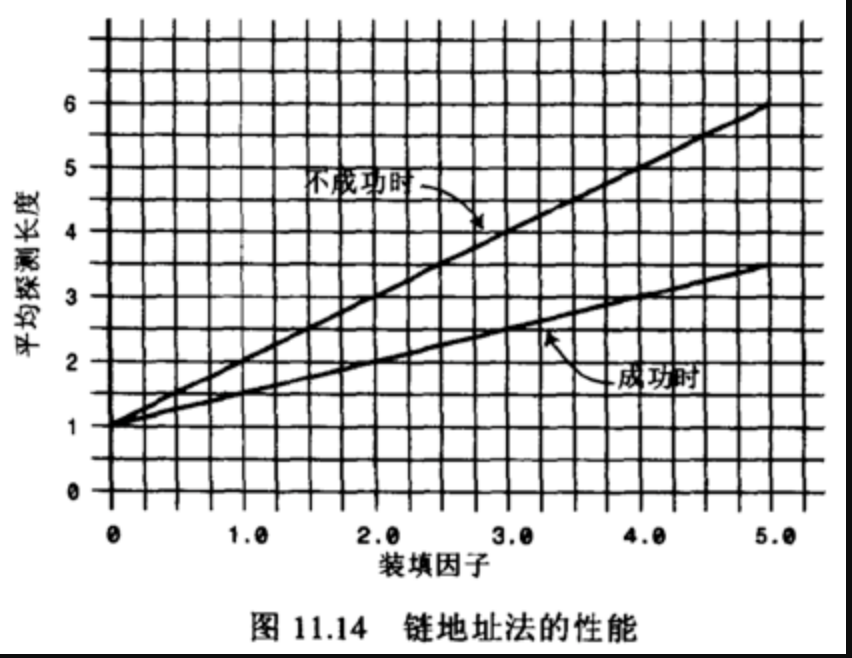
链地址法的效率分析有些不同, 一般来说比开放地址法简单. 我们来分析一下这个公式应该是怎么样的.
- 假如哈希表包含arraySize个数据项, 每个数据项有一个链表, 在表中一共包含N个数据项.
- 那么, 平均起来每个链表有多少个数据项呢? 非常简单, N / arraySize.
- 有没有发现这个公式有点眼熟? 其实就是装填因子.
- 成功可能只需要查找链表的一半即可: 1 + loadFactor/2
- 不成功呢? 可能需要将整个链表查询完才知道不成功: 1 + loadFactor.
# 效率的结论
经过上面的比较我们可以发现, 链地址法相对来说效率是好于开放地址法的。
所以在真实开发中, 使用链地址法的情况较多, 因为它不会因为添加了某元素后性能急剧下降。比如在Java的HashMap中使用的就是链地址法。
参考: 数据结构(九)之哈希表理论